Overview
We address the task of retrieving relevant images from a pre-collected dataset based on free-form natural language instructions for object manipulation or navigation. We define this task as Scene Text Aware Multimodal Retrieval (STMR), where the retrieved images may or may not contain scene text.
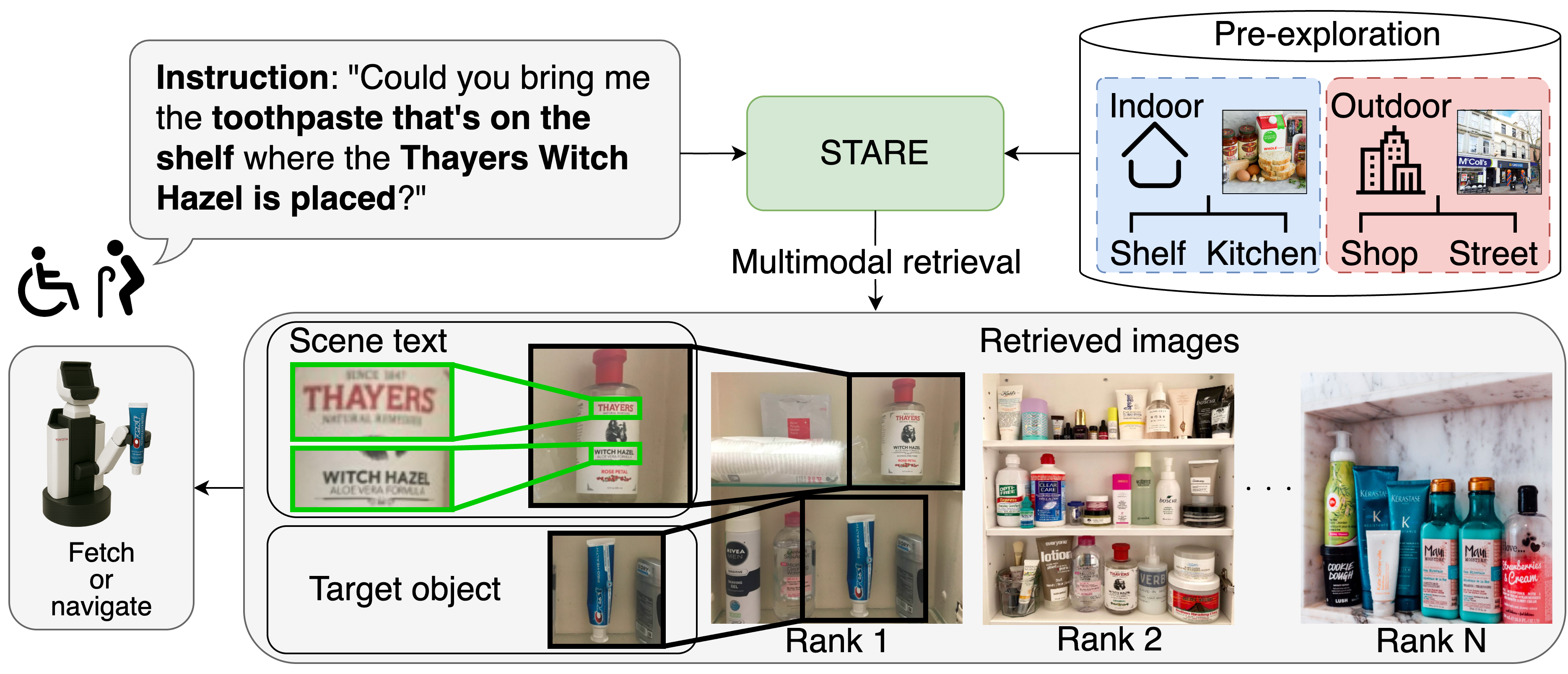
Fig. 1: Typical sample of STMR task. STARE retrieves target objects based on free-form language instructions using scene text and visual context.
To tackle the task, we propose a novel approach that
integrates scene text and visual features using Crosslingual
Visual Prompts (CVP) and a Scene Text Reranker—enhancing
retrieval based on free-form natural language instructions.
CORE NOVELTIES:
- Multi-Form Instruction Encoder captures complex concepts in user instructions by incorporating multi-level aligned language features, including structured descriptions generated by large language models (LLMs).
- Scene Text Aware Visual Encoder integrates scene texts into visual representations using Crosslingual Visual Prompt (CVP), overlapped patchified features, and multi-scale aligned features—producing narrative representations that highlight relevant text.
- Scene Text Reranker models the complex relationships between named entities (signifiers) and their corresponding objects (signified concepts), complementing similarity-based retrieval with semantically enriched reranking.
- Benchmarks: We construct the GoGetIt and TextCaps-test benchmarks, which contain navigation/manipulation instructions as well as images including scene texts.

Fig. 2: Overview of STARE. Given a natural language
instruction and a set of pre-collected images, the model retrieves
the most relevant images by integrating scene texts and visual
features through three modules: MFIE, STVE, and STRR.
Multi-Form Instruction Encoder (MFIE)
The MFIE models complex expressions within an instruction by incorporating multi-level aligned language features, including descriptions generated using world knowledge from LLMs.
Scene Text Aware Visual Encoder (STVE)
The STVE combines narrative representations that consider scene texts, overlapped patchified features, and multi-scale aligned features.
Scene Text Reranker (STRR)
The STRR efficiently models the highly complex relationships between signifiers and their corresponding signified expressions.
Ranked List
Finally, the model outputs a ranked list of images that are most relevant to the instruction. STARE is designed to handle both images with and without scene text, enabling flexible and robust retrieval in real-world environments.


